豪赌AI编程,万亿智谱瞄上下一座“高山”
21世纪经济报道记者 邓浩 陈归辞
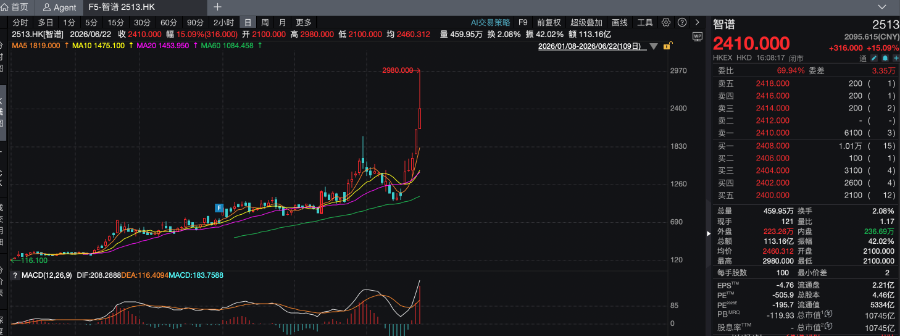
市值从百亿港元到冲破万亿港元,智谱只用了半年。市场甚至开始用“相当于三个美团、四个京东”来形容AI带来的剧烈震撼。
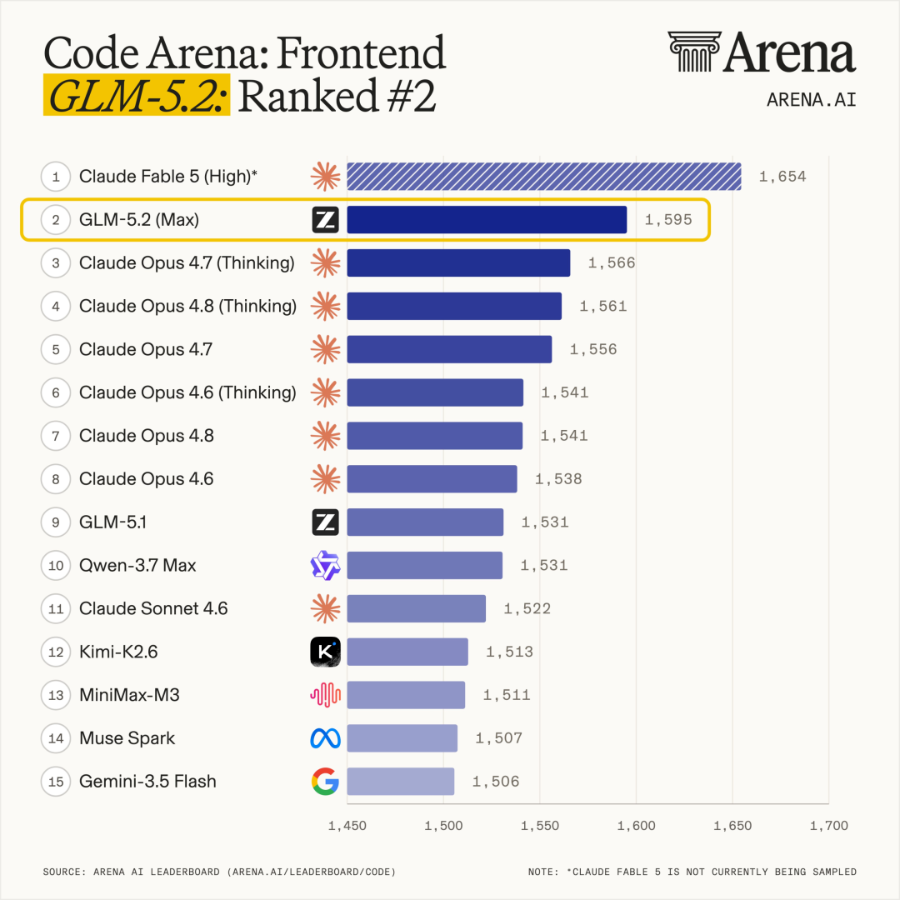
溢价的理由很简单,作为对标Anthropic的AI公司之一,智谱是AI编程领域极度稀缺的标的。在全球百万用户参与盲测的前端开发评估系统Code Arena上,其旗下的GLM-5.2取得全球可用模型第一的表现,领先国内玩家一个身位。
不过,不同于Anthropic的闭源策略,智谱选择开源路线来进行竞争。一个注脚是,不久前,当Anthropic因美国商务部禁令关闭两款最新模型的全球访问权限时,智谱随即上线并开源了GLM-5.2来“抢用户”。
(图片来源:wind)
哪条路线会最终取胜?目前尚未可知。
程序员中有一本流传已久的“圣经”《大教堂与集市》,书名隐喻了两种开发模式:前者由专属团队在封闭环境中控管,后者则依赖互联网上的公开协作。书中还提出了著名的林纳斯定律——“如果有足够多的眼睛,错误将无处遁形”。
某种程度而言,当Anthropic的“大教堂”把门锁上的时候,智谱的“集市”把路铺到了所有人脚边。
狙击Fable 5
长期以来,Anthropic都是美国大模型公司中对区域访问控制最严格的厂商之一,仅向官方支持地区开放Claude和API,而中国大陆等市场未被纳入名单。
2025年9月,Anthropic更是进一步收紧服务条款,将限制从地域封锁升级为所有权封锁,禁止由受限国家直接或间接持股超过50%的实体使用其服务。
2026年4月,公司又引入身份验证机制,要求部分用户提交政府签发证件以完成核验。
进入6月后,这种封锁局面进一步升级。当地时间6月9日,Anthropic震撼发布有史以来最强模型Claude Fable 5和Claude Mythos 5。但仅过了3天,Anthropic就接到美国商务部的一纸禁令,以“国家安全”为由,禁止所有外国国民访问这两款模型,甚至包括公司外籍员工。
禁令甫出,智谱几乎“零帧起手”,发布题为《致开发者:GLM-5.2全量开放,前沿智能属于所有人》的文章,开始“抢用户”。
“在一些前沿模型突然变得不可用的时刻,我们选择相信另一条路:前沿智能不应只属于少数人,也不应被少数规则随时收回。”这一表态的指向性,不言自明。
6月17日,智谱正式上线并开源GLM-5.2,以最宽松的MIT协议向全球开放,允许免费商用。
据发布数据,GLM-5.2聚焦长程任务能力,实现1M无损上下文;在1M上下文长度下,将单位token计算量降低至2.9倍;在相近token预算下,其Coding能力大致位于Claude Opus 4.7与Opus 4.8之间。
(图片来源:智谱官方公众号)
在长程编程基准FrontierSWE上,GLM-5.2取得74.4分,仅落后于Anthropic顶级闭源模型Opus 4.8约1个百分点,且超越GPT-5.5。
AI研究机构Proximal评价称,GLM-5.2是“第一个真正缩小了Anthropic/OpenAI与其他模型提供商之间巨大技术鸿沟的模型,也是目前为止最强的开源模型”。
值得注意的是,本次智谱卡点开放GLM-5.2并非智谱首次围绕Anthropic封锁进行接力补位。2025年9月,智谱也曾针对Anthropic升级封锁政策火速推出“Claude API用户特别搬家计划”。
两次精准卡位背后,是全球大模型开源与闭源两条路线深层角力的缩影。
自DeepSeek“横空出世”,掀起开源浪潮后,中国大模型行业逐步形成了“能力追赶+开源生态”的竞争路径。对多数国内厂商而言,在技术与全球商业化壁垒尚未完全建立的背景下,开源成为扩大开发者基础、提升模型渗透率的关键路径。
经过一年半的积累,在全球最大的模型聚合平台OpenRouter上,中国模型调用量占比已从2024年年底的约1.2%上升至目前的五成以上。上周最新的平台使用量排名中,DeepSeek、小米、MiniMax与腾讯的模型位居前四。
随着模型能力差距逐步收敛以及性价比优势的持续放大,开源路线的竞争力持续增强。在部分前沿模型服务出现可获得性与稳定性风险的背景下,开源模型在可本地部署与稳定性方面的优势也进一步凸显。
东方证券认为,开源模型凭借其开放权重、自主可控、可本地部署等特性,成为规避地缘政治风险、保障业务连续性的更优解。未来下游用户或将不再单纯追逐模型性能,而会更多转向稳定可用、自主掌控、持续可及的模型体系,这一趋势将直接推动开源生态份额提升。
一个有意思的细节是,智谱发布GLM-5.2后不久,一名X用户向独立研究员、AI开发博主提问“中国大模型何时能够达到Fable级别能力”。Teortaxes给出了7个月的时间差判断,而马斯克随即回复称,可能在2027年第一季度具备接近水平。
对此,智谱CEO唐杰直接表态:“不需要那么久。”
AGI之前的赛点
AGI是产业界争相攀登的终点,而通往AGI的道路,或许不只一条。AI编程作为可能的最短路径,吸引了市场极大的注意,不过对产业玩家来说,资源有限的情况下,侧重点仍有偏重。
6月初,AI编程领域的龙头Anthropic官宣已向美国证券交易委员会(SEC)秘密递交了首次公开募股(IPO)的S-1招股书草案,待SEC审核完成后将择机上市。
此前几天,Anthropic宣布以9650亿美元(约合人民币6.5万亿元)投后估值完成H轮650亿美元融资,这一估值水平也正式超过了OpenAI,成为全球估值最高的AI企业。
支撑估值的是强劲的营收能力。据Anthropic的CEO Dario Amodei披露,Anthropic自获得第一笔收入以来,每年收入增长约10倍,2026年5月已超过440亿美元。
国内某金融科技领域的资深从业者也对记者表示:“平时工作中一般用的是Anthropic的Claude,性能好很多,不过由于Claude对国内IP封禁比较厉害,所以有的时候也会选择国内的智谱。AI coding作为效率工具是刚需,一般一个数十人的团队,一个月花费几十万元很正常。”
值得注意的是,AI编程是一个典型的赢者通吃市场,用户对性能表现极其敏感,迁移成本又极低,对厂商而言,只有集中资源、专注性能提升才能维持头部地位。这可能是造成当前市场分化的一大原因。
据瑞银4月研报梳理,月之暗面(Moonshot AI)的Kimi系列专注于多智能体协作与复杂任务分解。MiniMax强调全栈多模态能力,同时具备出色的推理效率与成本控制能力。DeepSeek专注于数学推理、逻辑推理以及长文本上下文处理。
智谱则全力押注AI编程。智谱公开透露:“从2025年年初开始,我们几乎投入全部力量攻关Coding,历时大半年,细抠每一个代码环境的优化,终于迎来代码基座GLM-4.5,年底的GLM-4.7已经成为效果最好的国产Coding模型。”
这一选择与Anthropic不谋而合。在前述研报中,瑞银认为二者的模型开发战略高度契合。比如,在模型层对编码能力的专项聚焦:智谱和Anthropic均明确将编码作为模型能力前沿的核心方向,致力于在编码及开发者工作流程方面实现行业顶尖性能。而且,随着模型的持续迭代,智谱与Anthropic最新模型之间的差距正不断缩小,同时,两家公司对多模态技术(即音频和视频生成)的关注度均相对较低。
在瑞银看来,在AI编码领域的长周期任务解决能力,对现实世界的软件开发至关重要。因为软件开发涉及迭代式、多步骤的工作流程,需要可靠执行冗长的闭环任务,而非单轮生成。
根据METR此前的数据,Anthropic的Opus 4.6能实现约12小时的任务完成周期(成功率50%),而智谱的GLM-5.1则达到约8小时,在全球开源模型中排名第一,领先于多数国内同类模型。
这也为智谱所确认。在智谱看来,其目的是基于长程任务之上,让AI能够自主驱动、协同作业、7×24小时运转的智能体群体将成为新的生产力形态。从“智能助手”走向“数字员工”,构建包含成千上万个不同专业“性格”与“技能”的智能体社会,让它们自主辩论、协作、审查代码、调度资源,实现“自动驾驶”级别的数字生产力。
“代码还不是AGI,在通往AGI的路上,还有更多的高山需要翻越,下一座我们瞄向完全自治的智能体系统(Autonomous Agent System)。”智谱称。


